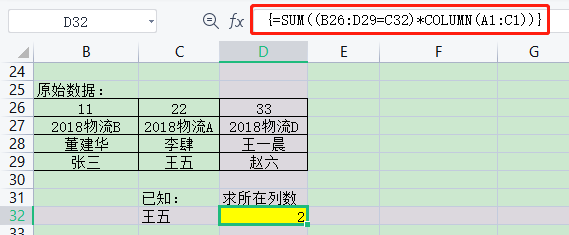
在一个网络的时代,爬虫可以通过网络抓取各种需要的信息,新闻头条,财经信息,具体的话可以收集相关公司的信息,以及平台的销售情况,商品热销,再到各类热售,秒杀等等。
爬虫就是获取网页并提取和保存信息的自动化程序
1,Python 提供了许多库来帮助我们实现这个操作,如 urllib、requests 等。我们可以用这些库来实现 HTTP 请求操作,请求和响应都可以用类库提供的数据结构来表示,得到响应之后只需要解析数据结构中的 body 部分即可,即得到网页的源代码,这样我们可以用程序来实现获取网页的过程了
2,采用正则表达式提取,这是一个万能的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,由于网页的结构有一定的规则,所以还有一些根据网页节点属性、CSS 选择器或 XPath 来提取网页信息的库,如 Beautiful Soup、pyquery、lxml 等。使用这些库,我们可以高效快速地从中提取网页信息,如节点的属性、文本值等。 3,将提取到的数据保存到某处以便后续使用。这里保存形式有多种多样,如可以简单保存为 TXT 文本或 JSON 文本,也可以保存到数据库,如 MySQL 和 MongoDB 等,还可保存至远程服务器,如借助 SFTP 进行操作等。
4,自动化程序,意思是说爬虫可以代替人来完成这些操作。首先,我们手工当然可以提取这些信息,但是当量特别大或者想快速获取大量数据的话,肯定还是要借助程序。爬虫就是代替我们来完成这份爬取工作的自动化程序,它可以在抓取过程中进行各种异常处理、错误重试等操作,确保爬取持续高效地运行。
https://cuiqingcai.com/17777.html
https://zhuanlan.zhihu.com/p/21479334
Python 爬虫技术的基本内容包括网页基础分析、requests 请求、XPath 和正则解析、Ajax 分析、Selenium 模拟浏览器爬取、Scrapy 等知识点
爬虫基本技术进行系统讲解,同时将最新前沿爬虫技术如异步、JavaScript 逆向、AST、安卓逆向、Hook、智能解析、群控技术、WebAssembly、大规模分布式、Docker、Kubernetes 等
|